决策树应用实战:泰坦尼克乘客生存预测
陈旸老师极客时间《数据分析实战45讲》笔记
sklearn 中的决策树模型
首先,我们需要掌握 sklearn 中自带的决策树分类器 DecisionTreeClassifier,方法如下:
clf = DecisionTreeClassifier(criterion='entropy')
到目前为止,sklearn 中只实现了 ID3 与 CART 决策树,所以我们暂时只能使用这两种决策树,在构造 DecisionTreeClassifier 类时,其中有一个参数是 criterion,意为标准。它决定了构造的分类树是采用 ID3 分类树,还是 CART 分类树,对应的取值分别是
entropy: 基于信息熵,也就是 ID3 算法,实际结果与 C4.5 相差不大;
gini: 默认参数,基于基尼系数。CART 算法是基于基尼系数做属性划分的,所以 criterion=gini 时,实际上执行的是 CART 算法。
算法的参数代表的含义如下:
| 参数 | 含义 |
|---|---|
| criterion | 特征选择的标准,有信息增益和基尼系数两种,使用信息增益的是ID3和C4.5算法(使用信息增益比),使用基尼系数的CART算法,默认是gini系数。 |
| splitter | 特征切分点选择标准,决策树是递归地选择最优切分点,spliter是用来指明在哪个集合上来递归,有“best”和“random”两种参数可以选择,best表示在所有特征上递归,适用于数据集较小的时候,random表示随机选择一部分特征进行递归,适用于数据集较大的时候。 |
| max_depth | 决策树最大深度,决策树模型先对所有数据集进行切分,再在子数据集上继续循环这个切分过程,max_depth可以理解成用来限制这个循环次数。 |
| max_features | 特征切分时考虑的最大特征数量,默认是对所有特征进行切分,也可以传入int类型的值,表示具体的特征个数;也可以是浮点数,则表示特征个数的百分比;还可以是sqrt,表示总特征数的平方根;也可以是log2,表示总特征数的log个特征。 |
| random_page | 随机种子的设置,与LR中参数一致。 |
| min_samples_split | 子数据集再切分需要的最小样本量,默认是2,如果子数据样本量小于2时,则不再进行下一步切分。如果数据量较小,使用默认值就可,如果数据量较大,为降低计算量,应该把这个值增大,即限制子数据集的切分次数。 |
| min_samples_leaf | 叶节点(子数据集)最小样本数,如果子数据集中的样本数小于这个值,那么该叶节点和其兄弟节点都会被剪枝(去掉),该值默认为1。 |
| min_weight_fraction_leaf | 在叶节点处的所有输入样本权重总和的最小加权分数,如果不输入则表示所有的叶节点的权重是一致的。 |
| max_leaf_nodes | 最大叶节点个数,即数据集切分成子数据集的最大个数 |
| min_impurity_decrease | 切分点不纯度最小减少程度,如果某个结点的不纯度减少小于这个值,那么该切分点就会被移除。 |
| min_impurity_split | 切分点最小不纯度,用来限制数据集的继续切分(决策树的生成),如果某个节点的不纯度(可以理解为分类错误率)小于这个阈值,那么该点的数据将不再进行切分。 |
| class_weight | 权重设置,主要是用于处理不平衡样本,与LR模型中的参数一致,可以自定义类别权重,也可以直接使用balanced参数值进行不平衡样本处理。 |
| presort | 是否进行预排序,默认是False,所谓预排序就是提前对特征进行排序,我们知道,决策树分割数据集的依据是,优先按照信息增益/基尼系数大的特征来进行分割的,涉及的大小就需要比较,如果不进行预排序,则会在每次分割的时候需要重新把所有特征进行计算比较一次,如果进行了预排序以后,则每次分割的时候,只需要拿排名靠前的特征就可以了。 |
这里我们只使用默认参数进行训练。
Titanic乘客生存预测
问题描述
泰坦尼克海难是著名的十大灾难之一,究竟多少人遇难,各方统计的结果不一。现在我们可以得到部分的数据,具体数据你可以从 GitHub 上下载:https://github.com/cystanford/Titanic_Data
其中数据集格式为 csv,一共有两个文件:
train.csv 是训练数据集,包含特征信息和存活与否的标签;
test.csv: 测试数据集,只包含特征信息。
现在我们需要用决策树分类对训练集进行训练,针对测试集中的乘客进行生存预测,并告知分类器的准确率。
在训练集中,包括了以下字段,它们具体为:
| 字段 | 描述 |
|---|---|
| PassengerId | 乘客编号 |
| Survived | 是否幸存 |
| Pclass | 船票等级 |
| Name | 乘客姓名 |
| Sex | 乘客性别 |
| SibSp | 亲戚数量(兄妹、配偶) |
| Parch | 亲戚数量(父母、子女) |
| Ticket | 船票号码 |
| Fare | 船票价格 |
| Cabin | 船舱 |
| Embarked | 登陆港口 |
生存预测的关键流程
我们要对训练集中乘客的生存进行预测,这个过程可以划分为两个重要的阶段:
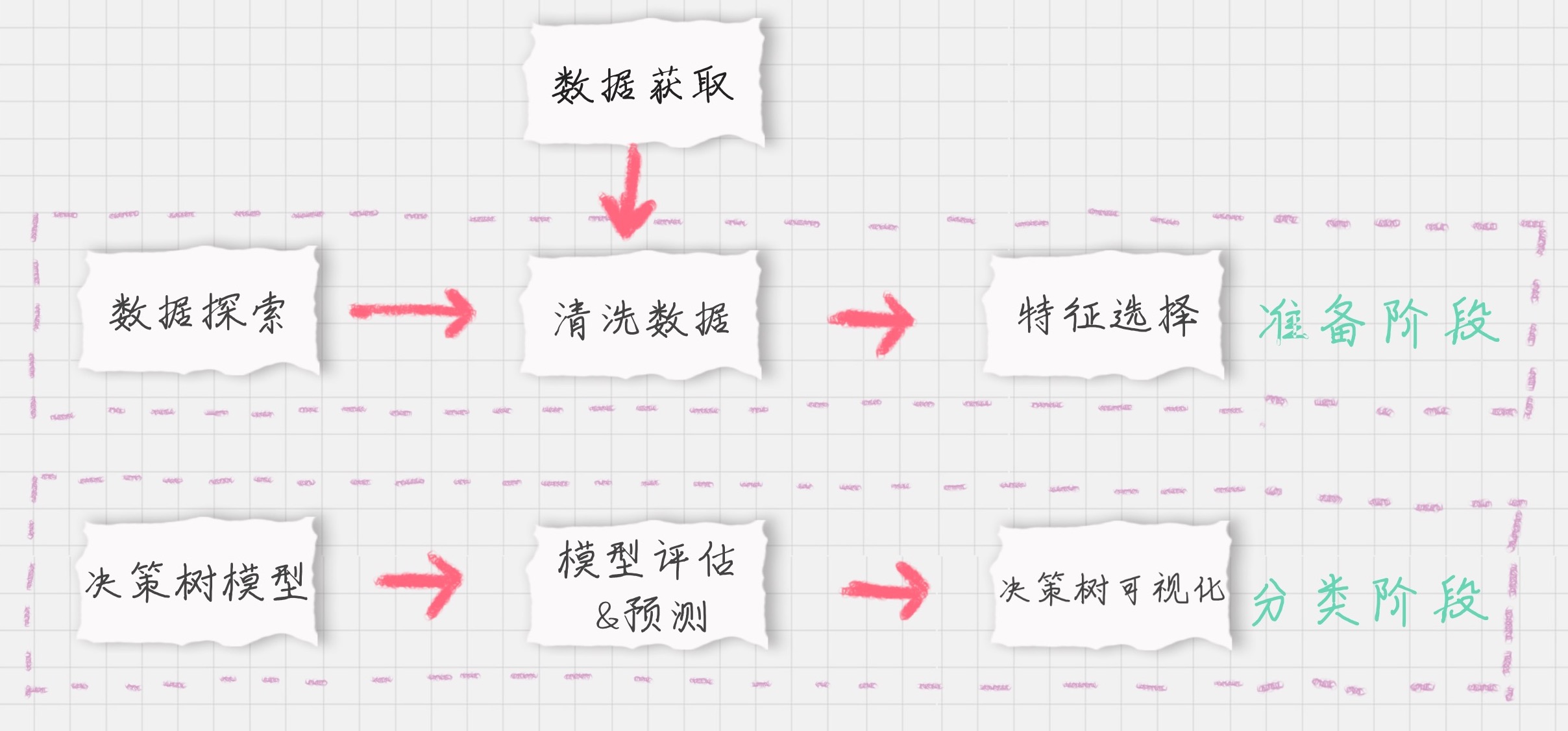
准备阶段: 我们首先需要对训练集、测试集的数据进行探索,分析数据质量,并对数据进行清洗,然后通过特征选择对数据进行降维,方便后续分类运算;
分类阶段: 首先通过训练集的特征矩阵、分类结果得到决策树分类器,然后将分类器应用于测试集。然后我们对决策树分类器的准确性进行分析,并对决策树模型进行可视化。
下面,我分别对这些模块进行介绍。
模块 1:数据探索
数据探索这部分虽然对分类器没有实质作用,但是不可忽略。我们只有足够了解这些数据的特性,才能帮助我们做数据清洗、特征选择。
那么如何进行数据探索呢?这里有一些函数你需要了解:
使用 info() 了解数据表的基本情况:行数、列数、每列的数据类型、数据完整度;
使用 describe() 了解数据表的统计情况:总数、平均值、标准差、最小值、最大值等;
使用 describe(include=[‘O’]) 查看字符串类型(非数字)的整体情况;
使用 head 查看前几行数据(默认是前 5 行);
使用 tail 查看后几行数据(默认是最后 5 行)。
我们可以使用 Pandas 便捷地处理这些问题:
import pandas as pd
import numpy as np
import os
base_dir=r'./titanic/'
train_dir=os.path.join(base_dir,'train.csv')
test_dir=os.path.join(base_dir,'test.csv')
train_data=pd.read_csv(train_dir)
test_data=pd.read_csv(test_dir)
print('train_data shape:',train_data.shape)
print('test_data shape:',test_data.shape)
# 数据信息
print(train_data.info())
print('-'*30)
print(test_data.info())
print('-'*30)
print(train_data.describe())
print('-'*30)
print(train_data.describe(include=['O']))
print('-'*30)
print(train_data.head())
print('-'*30)
print(train_data.tail())
模块2:数据清洗
通过上面程序得到的结果,发现Age、Fare、Cabin三个字段的数据有缺失。其中Age为年龄字段,为数值型,可以通过平均值进行补齐;Fare为船票价格,数值型,也可以通过平均价格补齐;而Cabin为船舱,缺失率很大(77%和78%),无法补齐,直接丢弃;Embarked为登陆港口有少量缺失值,使用众数补齐。
# 对年龄使用均值填充
train_data['Age'].fillna(train_data['Age'].mean(),inplace=True)
test_data['Age'].fillna(test_data['Age'].mean(),inplace=True)
# 对Fare使用均值填充
train_data['Fare'].fillna(train_data['Fare'].mean(),inplace=True)
test_data['Fare'].fillna(test_data['Fare'].mean(),inplace=True)
# 对Embarked使用众数填充
train_data['Embarked'].fillna('S',inplace=True)
test_data['Embarked'].fillna('S',inplace=True)
模块3:特征选择
特征选择是分类器的关键,特征选择不同,得到的分类器也不同。
通过数据探索发现,PassengerId为乘客编号,对分类没有作用,可以放弃;另外,Name、Cabin、Ticket这些字段也对分类没有逻辑上的贡献,都放弃,这样就挑出了特征字段:
features=['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
train_features=train_data[features]
test_features=test_data[features]
train_labels=train_data['Survived']
由于特征中的Embarked和Sex这些字段为字符串,因而需要转换为数值类型。使用sklearn中的DictVectorizer类可以将字符串类型的特征转换为数值类型:
from sklearn.feature_extraction import DictVectorizer
dvec=DictVectorizer(sparse=False)
train_features=dvec.fit_transform(train_features.to_dict(orient='record'))
print(dvec.feature_names_)
模块4:决策树模型
创建决策树模型来进行分类:
from sklearn.tree import DecisionTreeClassifier
clf=DecisionTreeClassifier(criterion='entropy')
clf.fit(train_features,train_labels)
模块5:模型预测&评估
test_features=dvec.fit_transform(test_features.to_dict(orient='record'))
pred_labels=clf.predict(test_features)
acc_decision_tree=round(clf.score(train_features,train_labels),6)
print('score 准确率为 %.4lf' %acc_decision_tree)
这里我们使用训练集做训练,再用训练集自身做准确率评估,故而准确率会很高,但无法对分类器在实际环境下的表现作出评估,因而改进为使用K折交叉验证来进行评估
from sklearn.model_selection import cross_val_score
score=np.mean(cross_val_score(clf,train_features,train_labels,cv=10))
print('{:.4f}'.format(score))
此时发现正确率大约为78%左右。
为了直观查看模型性能,绘制出ROC曲线:
train_labels=train_labels.values
train_labels=train_labels.reshape((train_labels.shape[0],1))
train_labels.shape
from sklearn.preprocessing import label_binarize
y_true=label_binarize(train_labels,classes=[3,2,1])
y_true=y_true[:,1:3]
print(y_true.shape)
print(y_true[:10,:])
from sklearn.metrics import roc_curve, auc
y_score=clf.predict_proba(train_features)
fpr,tpr,threshold = roc_curve(y_true.ravel(), y_score.ravel())
roc_auc = auc(fpr,tpr)
plt.figure()
plt.plot(fpr, tpr, color='darkorange',label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()

模块6:模型可视化
sklearn的决策树模型可以使用Graphviz工具进行可视化:

流程图
